A year ago, I got the opportunity to join DigitalOcean by the grace of Allah. And I took the chance to get on board the App Platform team.
So, what is App Platform? App Platform is DigitalOcean's serverless offering. Developers focus on their application, and we manage the infrastructure to run their apps properly and hassle-free. This is not like a service-based company; in fact, it's a product. Our alternatives include AWS Beanstalk + Lambda, GCP App Engine + Cloud Run, Heroku, and Vercel. So we kinda do what they do.
Getting a production server ready requires doing many things. For example:
-
Ensure the server has proper access so that random people can't SSH in or bruteforce/attempt alternative attacks
-
Configure domain/subdomain (if needed)
-
Ensure HTTPS
-
Prevent DDoS, malicious requests, bot attacks
-
Ensure zero downtime deployment, easy rollback if needed
-
CDN for static assets or content
-
Log analysis, alerting, monitoring
-
Auto scaling based on resource usage
-
Arrange for internal services that aren't connected to the outside world (ingress)
-
Queue worker, job setup
-
Secure connection for databases etc
These kinds of features are very essential for modern-day applications, but properly setting up and managing them is very time-consuming. Also, in many cases, dedicated (human) resources need to be hired. App Platform automates and manages these along with several other features.
My Contribution
My contribution is very small. A lot of beautiful work has been done here. Simple code that works. At the moment, I am currently the newest member of the team. However, the work here is quite diverse. It hardly gets boring.
Along with regularly maintaining our existing features, we work on new features. Although I can't talk about these features, we are a community cloud. One way to stay engaged with the community can be found at Ideas for App Platform. We look for what our users are telling us. If you have any ideas, you can share them here. Most of my work so far has been on the maintenance side.
Packets
One of my contributions has been directly solving customer problems. For example, once a customer complained that their app's database connection was failing very randomly. Well, although this might sound (and seem) normal, hunting it down… it was an adventure.
In the end, we had to do network packet capture with tcpdump and analyze it. I used wireshark for the analysis.
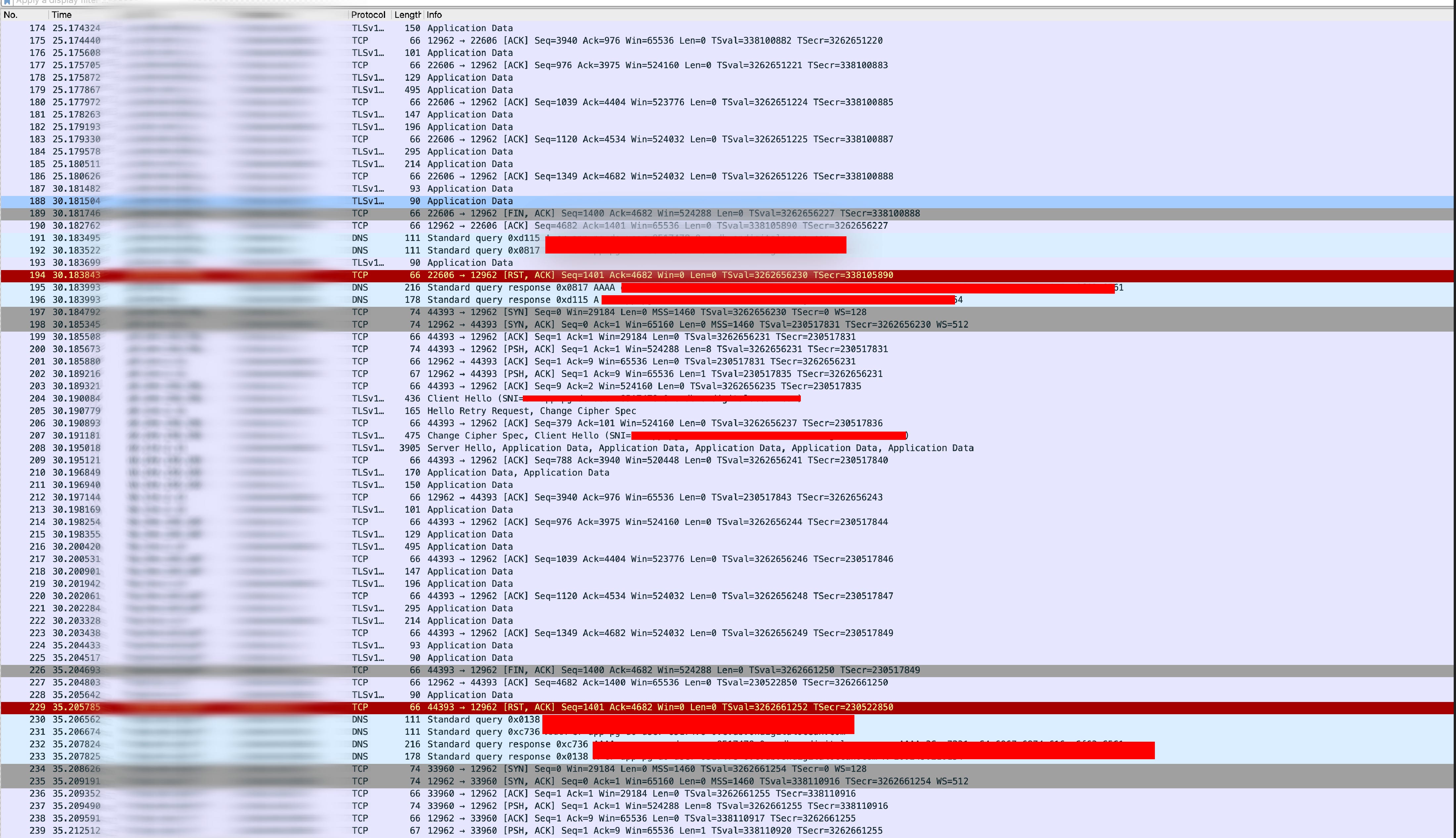
Note: this is not the actual packet capture but of one of my private networks. We can learn so much from packet captures. You should try it often if you have interest in these.
Benchmarking
Another interesting task was testing and documenting the load-bearing capability of our underlying infrastructure. Though can't say much about that, but 2 load testing tools were https://github.com/rakyll/hey and https://github.com/tsenart/vegeta.
Note: This is not the actual benchmark image
Kubernetes
The underlying infrastructure needs to be managed along with the features. DigitalOcean App Platform uses Kubernetes. Well, at one layer. Regularly maintaining Kubernetes and its components is part of the job. And for those who are new to DevOps/similar roles wanting to work with Kubernetes microservices but are still exploring, well, most of the time, it's not always that much fun.
Reading the release notes of each component, checking breaking changes, improvements, and security issues, testing them in different environments, and then slowly deploying them to clusters is often tiresome.
conntrack -L
And if the components fall behind once, catching up can be very troublesome. A lot of interesting things come with Kubernetes upgrades. For example, once after kube-proxy was updated, it was directly overriding conntrack. Our conntrack was set at another layer and it took 3 of us, 2 days to figure out.
Note: This is not the actual conntrack image
Besides these, another prominent task is investigation work. Something happened, we don't know why, and let's figure out why. Sometimes out-of-the-box solutions don't work either. For example, I'm working on a project where there's a POC going on to build something similar to the mechanism that Kubernetes uses to monitor desired vs current state for an internal task.
Terraform, RPC, Automation
Besides all these, various small tasks like updating terraform providers, making some changes in gRPC (since I came here, REST API hasn't been worked on; I guess this is the equivalent for that). Successfully migrating our PostgreSQL 12 users to PostgreSQL 13 or above (due to PostgreSQL coming to an End of Life last year). We often need to add/maintain various features in our internal tools. I really enjoy these bits; being able to automate is very fun. So much time-saving, not only for me but for everyone.
gVisor, Kata, cloud-hypervisor
Currently, I'm taking on another challenging (for me) task, which is maintaining our gVisor and kata container components. App Platform uses both in different places. And we use them so that bad actors can't exit from their container and tamper with other apps or cluster information + there are some other benefits. However, security is a big feature.
One problem + feature of gVisor is that if there's a problem in the Linux kernel, even knowing that, the same issue is implemented to maintain compatibility and exact behavior >_<. If you're wondering what gVisor is, gVisor is Google's user-space kernel.
There is always a tradeoff. One tradeoff of Container vs VM is security. And that is why projects like gVisor, kata container, cloud-hypervisor exist. And thanks to Allah that it does exist! This is currently one of my learning topics. I have close to zero idea about this.
In the future, I'll write more about Kubernetes, gVisor, kata, and many other things inshallah. If you're interested in these topics and like my writing style, you can subscribe.
Things I Like
I haven't had to write a single line of JavaScript here, haven't even seen it.
Our team, in fact DigitalOcean as a whole, is RFC driven. Before working on a feature, a lot of research is done about it—technical, non-technical, competitor analysis, UI, UX, security, scalability, etc., everything is documented. And we discuss these and move forward.
And the collaboration here is also amazing. No matter who is responsible for the feature, everyone gives input according to their ability. There are no silly questions. Everything is documented. Usually preceded or succeeded by a POC.
Another place for team collaboration is Pull request review. Here anyone can ask for code changes from anyone, even a junior engineer can ask a senior engineer to change code, can say that the code isn't clear or can be done differently, or this isn't right.
Team members; I think this is one of the best features. Folks here have amazing experience in different sectors and I'm able to learn a lot from everyone. And they really like to go in-depth. I'll share an incident.
Another Day at the Office
Once we got some alerts that a cluster ingress fail count had increased. But all the ingress nodes were up and running. The alert auto-resolved after a while. This happened 3-4 times. But why? While digging and discussing with our platform architect + now principal engineer, it was found that the bare-metal to which the hypervisor of the virtual machine of that node of that cluster was connected had failed on its primary ethernet and had fallen back to the secondary. Which doesn't give as much fast throughput as the primary.
Because of this, very few connections were dropped, but it didn't cross the threshold that would signal Kubernetes that nodes or even pods are failing. Kubernetes was retrying on its own (I think), which is why even if it failed a bit, the next one was successful. But our alert is based on success and failure, not on Kubernetes retries.
And all these network and hardware-related information are coming from a software engineer (our principal software engineer).
Fascinating? To me, it damn well is.
While on this topic, our alert system is quite aggressive? Proactive? Can't find the right word. But so far, all the problems that have occurred could have been much worse if these alerts weren't there.
Also, DigitalOcean is fully worldwide remote. Next time if someone says remote isn't possible, well, it's a management skill issue, mostly. Our team alone works with people from 5 different timezones. Also, for team synchronization, we don't have the time-wasting unnecessary meeting called daily standup.
Moreover, I'll say that having an engineer as a manager who works with similar technology is a blessing. And lastly, I'll say my most favorite part: I'm able to learn a lot. And I only have alhamdulillah to say.
From building apps for the cloud to building the cloud itself, the journey continues.
If you have any questions/suggestions, you can directly reach out at linkedin.com/thearyanahmed.
I'll often share these kinds of learnings along with my journey's learnings. If you are interested in reading, you can follow or subscribe. If you subscribe, you'll get articles in your inbox.